
안녕하세요
Whisper, LLM 기반 영상(유튜브) 요약 생성기 개발해보기 본문
*2023년 6월에 했던 과제 아카이브용 게시글입니다. 당시 사용된 모델을 현재 사용할 수 없어 24년 9월 기준으로 일부 수정했습니다.
과제 수행 이전에 영상에서 키워드를 추출하여 중요구간을 분석하는 과제를 한 적이 있었다. 그러나 단어가 등장하는 빈도수만으로 중요도를 매겨 키워드를 추출했기 때문에, 이 방법으로는 영상의 핵심 내용을 정확히 파악하는 데 한계가 있었다. 그런데 최근 영상 요약에 사용하기 좋은 딥러닝 모델이 공개되었다.
Whisper
68만 시간의 데이터를 학습한 자동음석인식(ASR)을 수행하는 딥러닝 모델이다. 다양한 언어가 학습되었는데 그중 한국어는 7번째로 많은 8,000시간을 학습시켰다(한국어는 A.I Hub(https://aihub.or.kr)데이터를 사용한 것으로 추측). 기존에 오픈된 ASR 모델들은 영어권 위주라 한국어로 모델을 학습하여 사용해야 했으나, Whisper는 한국어 데이터셋을 학습해 한국어 인식률이 높다. 자세한 내용은 아래에서 다루겠다.
GPT-4o mini
OpenAI에서 2024년 7월 18일 출시된 GPT-4o의 경량화 모델이다. API 가격은 100만 토큰 당 입력 0.15달러, 출력 0.60달러로 성능이 더 낮은 모델인 GPT-3.5보다도 저렴하다. 요약을 목적으로한 모델로 충분해보인다.
참고로 Google에서 제공하는 Gemini API를 사용하면 LLM 모델의 API를 사실상 무료로 사용할 수 있으므로, 요약 기능만 사용한다면 Gemini API를 사용하는 것을 추천한다. 아래에서는 GPT-4o의 다양한 기능 중 요약 기능을 이용할 것이다. (이미지에서는 GPT-3 turbo가 사용되므로 변경하여 사용해야 할 것이다)
Gemini API 사용에 관심이 있다면: https://ai.google.dev/gemini-api/docs/get-started/tutorial?hl=ko&lang=python
영상 요약을 위한 단계는
1. youtube-dl을 이용해 오디오 추출
2. 오디오를 작게 쪼개기(청크화)
3. whisper를 이용해 청크 전사(transliteration)하기
4. 전사된 청크를 GPT-3.5로 요약







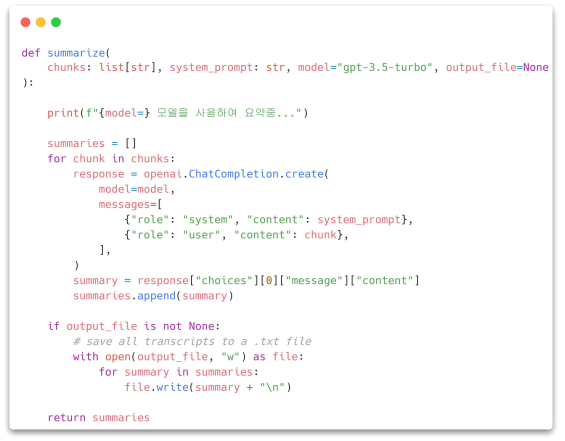


위를 기반으로 다음 영상을 요약하도록 요청하였다: https://youtu.be/w9YnsVkI980?si=xPgAe5rZWnsthx0O
긴 요약:
- 구글은 GPT가 주가에 부정적인 영향을 미치자 PaLM 모델을 출시했습니다.
- PaLM은 사용자 친화적인 인터페이스로 보다 쉽게 사용할 수 있는 LLM 모델입니다.
- PaLM2는 성능이 우수하고 다양한 언어와 데이터셋으로 학습된 모델입니다.
- PaLM2는 이전 모델인 PAM 및 GPT4보다 더 나은 성능과 더 작은 모델 크기를 보여줍니다.
- PaLM2는 모델 크기가 작기 때문에 클라우드 기업에게 GPT4에 비해 비용 효율적일 수 있습니다.
- 코드 보안, 의학 지식, 자연어 처리 등 다양한 분야에 활용 가능
- PaLM2는 GPT4보다 언어 이해 능력이 우수합니다.
- 더 큰 모델 크기와 컴퓨팅 파워 요구 사항을 수용하기 위해 GPT4의 비용이 크게 증가했습니다.
- PaLM2는 즉각적인 엔지니어링 기술 없이도 사용할 수 있습니다.
- PaLM2는 다양한 분야에서 윤리적이고 실용적인 사용 사례의 잠재력을 가지고 있습니다.
짧은 요약:
Google은 더 쉬운 사용과 언어 이해 성능을 위해 설계된 LLM의 개선된 버전인 PaLM이라는 새로운 모델을 출시했습니다. 후속 모델인 PaLM2는 모델 크기와 비용 효율성 측면에서 PaLM과 GPT4를 능가하는 성능으로 클라우드 기업에게 더욱 실용적인 옵션이 될 것입니다. 다양한 분야에서 잠재적으로 사용될 수 있으며 작동에 즉각적인 엔지니어링 기술이 필요하지 않습니다.
Whisper 살펴보기
위에서 사용된 Whisper는 OpenAI의 새로운 음성 인식 모델이다. 이전에 있었던 모델과 대비 해 Whisper는 무엇이 다를까?
첫 번째, 훈련에 막대한 양의 데이터를 사용하였다.
두 번째, 이전에 자체 지도를 통해 학습한 모델들과는 다른 방식으로 학습했다.
세 번째, 음성인식 파이프라인에 필요한 모든 것을 하나의 모델로 생성하도록 학습했다.
아래에서 이어 설명하겠다.
Whisper 학습 데이터
예전부터 음성인식 모델은 지속적으로 개선되어 인간보다 낮은 단어 오류율(WER)을 달성했 다. 그런데 유튜브 자동음성인식으로 전사한 결과물을 보면, 정확하게 인식된 결과를 거의 본 적 없을 것이다. 인간보다 낮은 단어 오류율을 달성했는데, 왜 이런 결과가 나올까?
유튜브 음성인식과 같이 많은 자동음성인식(이하 ASR) 모델들은 리브리스피치(Librispeech)라 는 데이터셋을 사용해 학습된다. 리브리스피치는 960시간의 분량의 데이터셋으로, 존재할 수 있는 모든 음성 데이터에 비해 낮은 분포를 보인다. 또한 이런 모델은 리브리스피치 테스트셋 에서 테스트되기 때문에 같은 분포 안에서만 학습된다.

Whisper는 이를 보완하기 위해 인터넷에 존재하는 68만 시간 분량의 음성 데이터를 학습하 는 방법으로 접근했다. Whisper는 학습한 데이터의 분포 외의 Librispeech 테스트셋에서 추론하여 학습한다. Whisper의 성능은 다양하게 분산된 엄청난 양의 데이터 덕분이다. 데이 터 분량을 단순 계산하면 77.6년 분량의 데이터셋인 것이다.

Whisper 아키텍쳐
Whisper는 이전 ASR모델과 비슷한 트랜스포머 기반 인코더-디코더 모델이다. 오디오 스펙트 로그램(Spectrogram)의 특징을 텍스트 토큰과 매핑시킨다.

먼저, 원본 오디오가 입력되면 특징 추출기에 의해서 Mel 스펙트로그램으로 변환된다. 그 다 음 인코더가 스펙트로그램을 인코딩하여 시퀀스를 형성하고, 디코더가 이전 토큰과 시퀀스에 따라 텍스트 토큰을 회귀하여 예측한다.
인식률 개선하기
영어 이외의 언어로 Whisper를 사용할 시 결과물에서 가끔 오타 같은것이 생기는 경우가 있다. 모델을 WER(Word Error Rate)로 점수를 매길 때 이런 요소 때문에 오류율이 높게 나오게 될 것이다. 이런 오류는 왜 발생할까? 가능성 중 하나를 이야기 해보자면, 모델이 이런 오타같은 오류까지 학습한 경우이다.
예를 들어 다른 음성인식모델에서 생성된 결과물이 훈련 데이터에 포함되었을 경우가 있을 것이다. 이럴 경우 개선 방법에는 무엇이 있을까?
첫 번째로 오류가 없는, 검증된 ASR 결과물(트랜스스크립션) 데이터셋을 사용해 모델을 미세 조정하는 방법을 통해 오류율을 줄이는 방법이 있을 것이다.
두 번째로 Whisper에서 많은 후보 문장을 출력하게 한 뒤, 외부 언어모델(GPT-3 같은)을 사용하여 순위를 매겨 채택함으로써 정확도를 향상시키는 방법이 있을 것이다.
세 번째는 Whisper의 디코더에 외부 언어모델을 추가하여 결과물의 문법을 향상시키는 방법이다. 두 번째 방법과 비슷한 느낌일 것이다. (https://github.com/openai/whisper/discussions/266)
Misspelled output · openai whisper · Discussion #266
I'm trying to transcribe greek audio and have some strange results. Some common words are misspelled. Example : "κόδικας" should have been written "κώδικας" ( κώδικας -> English means Code) "Άγγυρα...
github.com
마치며
10개 정도의 영상을 테스트 해보았고, 테스트한 모든 영상에서 요약문을 문제없이 생성했다. 위에서 출력된 요약문을 예로 들어 PaLM을 PAM으로 인식하는 등 제품 및 이름 식별에 문제가 있었지만, 그 외에는 문제가 없었기 때문에 매우 만족했다.
위 코드를 강의 및 교육 영상에 활용함으로써 핵심 내용을 빠르게 파악하는 데 활용할 수 있을 것이다. 학생들은 빠르게 학습하여 시간을 절약할 수 있을 것이고, 연구자 및 교육자 또한 강의 자료와 연구 영상에 활용함으로써 내용을 빠르게 흩어보고 파악할 수 있을 것이다.
또한 프롬프트를 개인이 원하는 대로 수정할 수 있기 때문에, 요약문을 내가 원하는 수준과 스타일에 맞춰 출력하도록 요구할 수 있다. 이를 통해 학습자에게 개인화된 경험을 제공할 수 있을 것이다.
'삽질' 카테고리의 다른 글
| pyautogui 에서 activate() 안될 경우 해결 방법 (0) | 2024.12.25 |
|---|---|
| 리눅스 서버에서 인터넷 안될 때 의심해볼 것 (4) | 2024.10.17 |
| SLURM 노드 unk* idle* down* 상태 / error: nodes not responding (1) | 2024.03.04 |
| MeCab 경로 인식 문제 해결 (0) | 2023.12.09 |
| Pandas로 CSV 파일에서 숫자 데이터를 문자열이 아닌 숫자로 불러오기 (0) | 2023.10.05 |
